The ACID properties guaranteed by database systems have greatly simplified the development of data processing applications. These properties provide an application with an illusion of exclusive access to the database besides transparently handling different kinds of failures. In this post, I will attempt to highlight the benefits of providing a subset of the ACID properties as desired by the application.
ACID stands for Atomicity, Consistency, Isolation, and Durability.
Atomicity ensures that either all the operations of a transaction commit or none of them do. The programmer, therefore, does not need to handle the effects of incomplete database state transitions inside the application. This simplifies error handling.
Applications often require the data to satisfy certain constraints at all times. Consistency refers to such application-specific guarantees. Offloading constraint checking to the DBMS reduces application complexity. When the effects of a transaction do not satisfy a constraint, the DBMS prevents it from mutating the database.
Isolation is a powerful abstraction. It allows the programmer to assume that the application has exclusive access to the database. This obviates the need for the application to deal with the “dirty data” generated by other applications that are concurrently accessing the DBMS.
Durability guarantees that the changes made by a committed transaction will be visible to all subsequent transactions in the DBMS, even after a system or media failure. Thus, the programmer need not worry about data loss in case of such failures.
The ACID properties in tandem provide functionality that is often required in most data processing applications. Instead of duplicating this logic in each application, we can offload it to the DBMS.
Now, do applications always need all these four properties?
Perhaps an application is processing a transient database that can be regenerated from source when needed. It clearly does not require the durability property. It suffices for the DBMS to only provide the ACI properties for this application. If the application were to let the DBMS know that it does require the durability property, then the DBMS could deliver higher performance for the application. Why is this the case? How about the other properties?
In order to answer these questions, we need a high-level understanding of how a DBMS generally guarantees these properties. Let’s consider the following example. The database consists of only one table – an EMPLOYEE table – as shown in Figure 1. This table has three columns “ID”, “NAME”, and “BALANCE”. It contains information associated with four employees.
Next, let’s look at the isolation property. The “transaction manager” inside the DBMS maintains “locks” for each employee record. Before modifying a record, it grabs the locks associated with the employee records #2 and #4 so that no concurrent application can change them, as shown in Figure 2. After committing the changes made by the transaction in the database, it releases the locks that it had grabbed so that other applications waiting on those locks can proceed. This property gives the application the illusion of exclusive access to the database.
The “consistency manager” is responsible for ensuring that every transaction leaves the database in a consistent state wherein all the application-specific constraints hold. In this example, the consistency manager ensures that the total balance of all employees equals $1000 before committing the transaction.
At the time of committing a transaction, the “log manager” ensures the durability of the changes made by the transaction by recording the “after images” of the employee records in a persistent “redo log” that is stored on a durable storage device like a disk. For this particular transaction, the after image of the BALANCE column in employee record #2 is “100”.
If you would like to dig deeper into these different modules of a DBMS, I would recommend taking the excellent guided tour in the Architecture of a Database System.
Now that we grok how the DBMS ensures the ACID properties, let’s consider the implications of not supporting the durability property. In this scenario, the DBMS need not persist the “after images” of modified records in the redo log on disk. This improves the performance of the DBMS as it no longer needs to write to disk when committing the changes made by transactions.
Let’s consider another example – an application running on an IOT device that is using a dedicated DBMS and does need perform concurrent writes. This application does not require the isolation property of the DBMS. Consequently, the DBMS can disable its transaction manager for this application.
What if an application requires durability but not atomicity? In this case, the DBMS can directly apply the changes on the database instead of first recording them in the “undo log”. However, it still needs to propagate those changes to the “redo log”.
These examples should, hopefully, persuade the reader that “dropping” the ACID properties that are not needed by the application can help improve the performance of the DBMS.
The shared functionality in modern applications has grown beyond the ACID properties. Security, data distribution, data compression and auto tuning are some features that are often required by these applications. It would be nice to have standard interfaces for exposing this functionality to the application.
In their seminal paper on RISC-style database systems, the authors make the case for building database systems with simpler RISC-style modules. Each module should have a well-defined and relative narrow functionality so that they can be flexibly “glued together” depending on the needs of the application. The authors illustrate this RISC philosophy using a compelling multi-layered query processing engine.
This design paradigm can perhaps be employed at a higher layer of abstraction. A DBMS could have a clean and extensible module-based architecture wherein the application can enable only those modules that provide the desired functionality. For instance, as shown in Figure 3, if an application only needs the atomicity, durability, and security features, then the DBMS can either disable or adapt the other modules for this application based on this information. Simplifying the architecture of DBMSs in this manner would allow a wider variety of data processing applications to benefit from their functionality.
The functionality that modern data processing applications expect from the DBMS has grown beyond that guaranteed by the ACID properties. These applications often have a specific set of requirements that cannot be met by merely tweaking the DBMS configuration. A clean and extensible RISC-style DBMS architecture would go a long way in better supporting the demands of these applications.
[1] Principles of Transaction-Oriented Database Recovery, Theo Haerder and Andreas Reuter, Computing Surveys, 1983
[2] Architecture of a Database System, Joseph M. Hellerstein, Michael Stonebraker, and James Hamilton, Foundations and Trends in Databases, 2007.
[3] Rethinking Database System Architecture: Towards a Self-Tuning RISC-Style Database System, Surajit Chaudhuri and Gerhard Weikum, VLDB, 2000.
WHAT IS ACID?
ACID stands for Atomicity, Consistency, Isolation, and Durability.
Atomicity ensures that either all the operations of a transaction commit or none of them do. The programmer, therefore, does not need to handle the effects of incomplete database state transitions inside the application. This simplifies error handling.
Applications often require the data to satisfy certain constraints at all times. Consistency refers to such application-specific guarantees. Offloading constraint checking to the DBMS reduces application complexity. When the effects of a transaction do not satisfy a constraint, the DBMS prevents it from mutating the database.
Isolation is a powerful abstraction. It allows the programmer to assume that the application has exclusive access to the database. This obviates the need for the application to deal with the “dirty data” generated by other applications that are concurrently accessing the DBMS.
Durability guarantees that the changes made by a committed transaction will be visible to all subsequent transactions in the DBMS, even after a system or media failure. Thus, the programmer need not worry about data loss in case of such failures.
The ACID properties in tandem provide functionality that is often required in most data processing applications. Instead of duplicating this logic in each application, we can offload it to the DBMS.
A CASE FOR SPLITTING ACID
Now, do applications always need all these four properties?
Perhaps an application is processing a transient database that can be regenerated from source when needed. It clearly does not require the durability property. It suffices for the DBMS to only provide the ACI properties for this application. If the application were to let the DBMS know that it does require the durability property, then the DBMS could deliver higher performance for the application. Why is this the case? How about the other properties?
In order to answer these questions, we need a high-level understanding of how a DBMS generally guarantees these properties. Let’s consider the following example. The database consists of only one table – an EMPLOYEE table – as shown in Figure 1. This table has three columns “ID”, “NAME”, and “BALANCE”. It contains information associated with four employees.
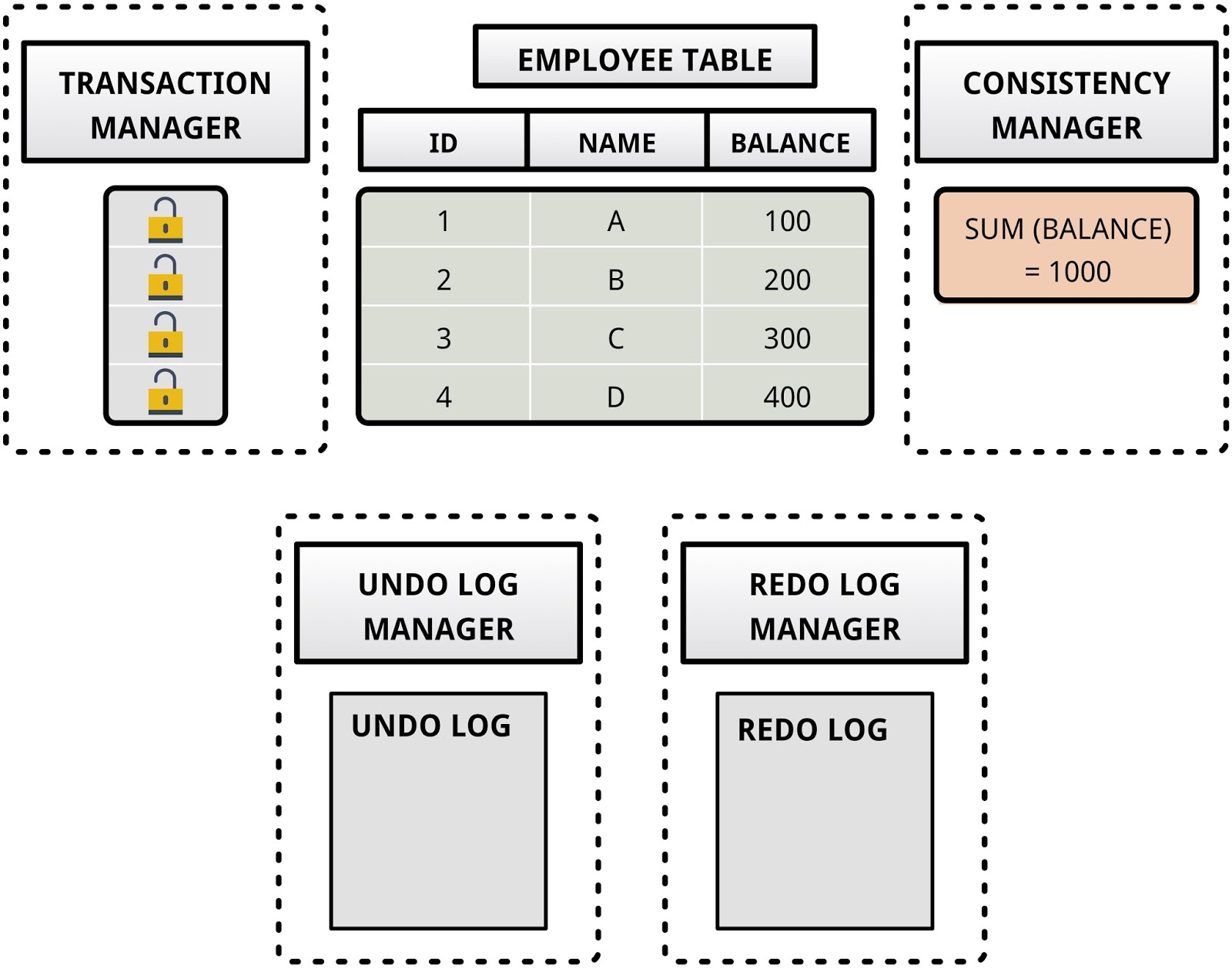 |
| Figure 1: How does a DBMS ensure the ACID properties? |
We will focus on an application for transferring money between employees. Consider a transaction that attempts to transfer 100 dollars from employee #2 to employee #4. To make things more interesting, let the application require the DBMS to ensure that the total balance of all employees equals $1000.
Let’s now look at how a DBMS ensures the ACID properties for this application. Consider the atomicity property. We need a mechanism to “undo” the changes made by a transaction in case of a failed transfer. The “log manager” of the DBMS takes care of this by recording the “before images” of the modified employee records in a separate “undo log” before modifying the database. For this particular transaction, the before image of the BALANCE column in employee record #2 is “200”. This is illustrated in Figure 2.
 |
| Figure 2: How does a DBMS ensure the ACID properties? |
Next, let’s look at the isolation property. The “transaction manager” inside the DBMS maintains “locks” for each employee record. Before modifying a record, it grabs the locks associated with the employee records #2 and #4 so that no concurrent application can change them, as shown in Figure 2. After committing the changes made by the transaction in the database, it releases the locks that it had grabbed so that other applications waiting on those locks can proceed. This property gives the application the illusion of exclusive access to the database.
The “consistency manager” is responsible for ensuring that every transaction leaves the database in a consistent state wherein all the application-specific constraints hold. In this example, the consistency manager ensures that the total balance of all employees equals $1000 before committing the transaction.
At the time of committing a transaction, the “log manager” ensures the durability of the changes made by the transaction by recording the “after images” of the employee records in a persistent “redo log” that is stored on a durable storage device like a disk. For this particular transaction, the after image of the BALANCE column in employee record #2 is “100”.
If you would like to dig deeper into these different modules of a DBMS, I would recommend taking the excellent guided tour in the Architecture of a Database System.
Now that we grok how the DBMS ensures the ACID properties, let’s consider the implications of not supporting the durability property. In this scenario, the DBMS need not persist the “after images” of modified records in the redo log on disk. This improves the performance of the DBMS as it no longer needs to write to disk when committing the changes made by transactions.
Let’s consider another example – an application running on an IOT device that is using a dedicated DBMS and does need perform concurrent writes. This application does not require the isolation property of the DBMS. Consequently, the DBMS can disable its transaction manager for this application.
What if an application requires durability but not atomicity? In this case, the DBMS can directly apply the changes on the database instead of first recording them in the “undo log”. However, it still needs to propagate those changes to the “redo log”.
These examples should, hopefully, persuade the reader that “dropping” the ACID properties that are not needed by the application can help improve the performance of the DBMS.
TOWARDS A RISC-STYLE DBMS ARCHITECTURE
Let’s now consider another interesting question. Many data processing
applications, certainly, require the functionality associated with the
four ACID properties. However, are these the only properties required by
data processing applications?
The shared functionality in modern applications has grown beyond the ACID properties. Security, data distribution, data compression and auto tuning are some features that are often required by these applications. It would be nice to have standard interfaces for exposing this functionality to the application.
In their seminal paper on RISC-style database systems, the authors make the case for building database systems with simpler RISC-style modules. Each module should have a well-defined and relative narrow functionality so that they can be flexibly “glued together” depending on the needs of the application. The authors illustrate this RISC philosophy using a compelling multi-layered query processing engine.
This design paradigm can perhaps be employed at a higher layer of abstraction. A DBMS could have a clean and extensible module-based architecture wherein the application can enable only those modules that provide the desired functionality. For instance, as shown in Figure 3, if an application only needs the atomicity, durability, and security features, then the DBMS can either disable or adapt the other modules for this application based on this information. Simplifying the architecture of DBMSs in this manner would allow a wider variety of data processing applications to benefit from their functionality.
 |
| Figure 3: List of application requirements |
TAKEAWAYS
The functionality that modern data processing applications expect from the DBMS has grown beyond that guaranteed by the ACID properties. These applications often have a specific set of requirements that cannot be met by merely tweaking the DBMS configuration. A clean and extensible RISC-style DBMS architecture would go a long way in better supporting the demands of these applications.
REFERENCES
[1] Principles of Transaction-Oriented Database Recovery, Theo Haerder and Andreas Reuter, Computing Surveys, 1983
[2] Architecture of a Database System, Joseph M. Hellerstein, Michael Stonebraker, and James Hamilton, Foundations and Trends in Databases, 2007.
[3] Rethinking Database System Architecture: Towards a Self-Tuning RISC-Style Database System, Surajit Chaudhuri and Gerhard Weikum, VLDB, 2000.
No comments :
Post a Comment